Forfattere

Du har sikkert hørt om ChatGPT eller måske endda allerede brugt det. ChatGPT er en interaktiv chatbot, der kan generere detaljerede svar på alle mulige spørgsmål. Den kan endda skrive dine skoleopgaver for dig. Men hvordan ved den, hvordan den skal besvare dine spørgsmål så detaljeret? ChatGPT består af neurale netværk, der gør det muligt for chatbotten at besvare dit spørgsmål. I denne artikel vil vi se nærmere på disse neurale netværk.
Neurale netværk bruges overalt i dag. De ændrer brugerinput gennem en algoritme bestående af avanceret matematik, for at generere noget nyttigt. Chatbots som ChatGPT er baseret på neurale netværk. Desuden bruger Netflix et neuralt netværk til at anbefale nye film og serier, du kan se. Indgangen til netværket er de film/serier, du allerede har set. Som output dukker film/serier, du ikke har set, op i dine anbefalinger. Påvisning af hudkræft er et andet eksempel på, hvordan neurale netværk kan bruges. Nogle telefonapplikationer giver dig mulighed for at tage et billede af en hudmodermærke. Et neuralt netværk vil derefter fortælle dig risikoen for, at denne modermærke er kræftagtig.
Forestil dig, at du ser en blomst af irisplanten, som har mange underarter. Hvis du vil vide, hvilken underart det er, kan du tage et billede med Google Lens for at få svaret. Denne app bruger en slags neuralt netværk. Men hvordan afgør et sådant netværk den korrekte underart af iris på dit billede? Der er tre underarter, der ligner hinanden meget: setosa, versicolor og virginica. De har bægerblade og kronblade, som du kan se i figur 1A. Vi kan måle længden og bredden af disse bægerblade og kronblade (i centimeter) og samle disse oplysninger i et datasæt. Figur 1B viser målinger fra seks tilfældigt udvalgte blomster, to for hver underart, fra det samlede datasæt på 150 observationer. Som du kan se, er længderne og bredderne ikke de samme for hver underart. Når vi arbejder med neurale netværk, kalder vi blomstens karakteristika (såsom bægerbladets længde) for træk, mens underarterne kaldes kategorier. Tanken er, at vi vil bruge disse træk til at finde ud af, hvilken kategori irisblomsten tilhører. Vi kalder dette for “forudsigelse” (prøv nu øvelse 1 i boks 1).
(I hele artiklen vil du støde på øvelser. Du kan prøve at besvare disse spørgsmål for at tjekke din forståelse.) Prøv at finde nogle mønstre i blomsterdatasættet i figur 1b. Fokuser på kronbladets og bægerbladets bredde. Hvordan adskiller disse træk sig for hver undertype?
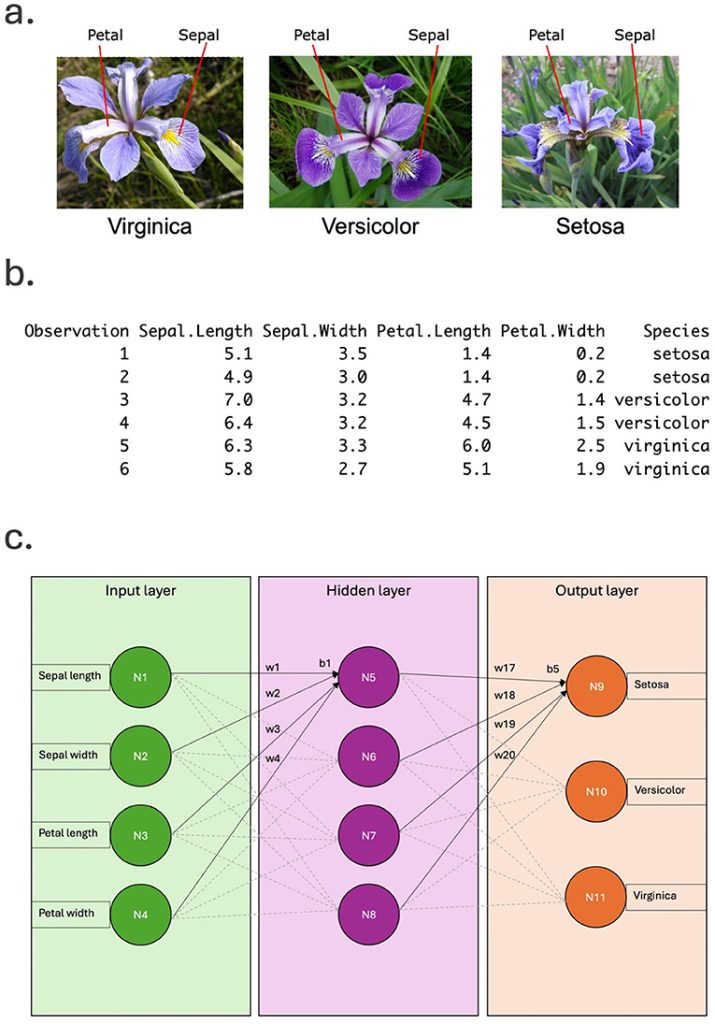
For at hjælpe dig med at forstå neurale netværk skal vi først tale om, hvad et neuralt netværk består af [1, 2]. En af de vigtigste komponenter kaldes neuroner (deraf navnet “neuralt netværk”), fordi deres funktion er inspireret af nerveceller i hjernen, der kaldes neuroner [3]. Figur 1C viser en oversigt over et neuralt netværk, der kunne bruges til at analysere blomsterdataene. Neuronerne er repræsenteret af cirkler. Ethvert neuralt netværk har altid et indgangslag og et udgangslag. I indgangslaget (grønt) er antallet af neuroner altid lig med antallet af træk, så i vores tilfælde er der fire neuroner (N1, N2, N3 og N4). For outputlaget (orange) er antallet af neuroner altid lig med antallet af kategorier, i vores tilfælde tre (N9, N10 og N11), svarende til de tre blomsterundertyper (prøv nu øvelse 2 i boks 2).
Et andet velkendt eksempel er at lade et neuralt netværk forudsige håndskrevne cifre fra 0 til 9. Hvor mange output-neuroner ville et sådant netværk have?
Neurale netværk indeholder også andre/mellemlag (lilla), der kaldes skjulte lag, med et bestemt antal neuroner. Disse lag behandler inputtet for at generere outputtet. Der kan være så mange skjulte lag, som du ønsker, i netværket. Hvert skjult lag kan også indeholde så mange neuroner, som du ønsker. For vores data vil et skjult lag med et relativt lille antal neuroner (fire) fungere godt. Hvert neuron i et lag har forbindelser til hvert neuron i det næste lag (vist med pilene). For eksempel har neuron N5 i det skjulte lag forbindelser til alle fire neuroner i indgangslaget.
I praksis er disse forbindelser faktiske tal, og vi kalder dem vægte (w1, w2 osv.). Antallet af vægte svarer altså til antallet af forbindelser. Formålet med disse vægte er at omdanne inputværdierne (kronbladets længde, bredde osv.) til forskellige tal. Dette hjælper netværket med at afgøre, hvilken kategori blomsten tilhører. Du kan også tænke på vægtene som styrken af forbindelsen mellem neuroner. En stor værdi betyder altså, at neuronet har stor indflydelse på det forbundne neuron. Hvert neuron, undtagen inputneuronerne, har også et andet tal, der kaldes en bias (b1, b5 osv.), der yderligere hjælper med at bestemme kategorien. Dette tal justerer grundlæggende resultaterne fra vægtene for at gøre netværket mere fleksibelt. For eksempel styrker en stor bias yderligere den pågældende neurons rolle (prøv nu øvelse 3 i boks 3).
Prøv at finde ud af det samlede antal vægte og bias for netværket i figur 1C.
Hvordan bestemmer det neurale netværk kategorien ud fra blomstens egenskaber? Hvis vi for eksempel indtastede bredde- og længdeværdierne fra den første række i figur 1B, hvordan ville netværket så vide, at dette er en setosa-blomst? For at hjælpe dig med at forstå dette skal vi tale om træning og test af et neuralt netværk.
Først deler vi datasættet tilfældigt op i et træningssæt og et testsæt. Generelt bør træningssættet være større end testsættet. Flere træningsdata fører som regel til mere nøjagtige forudsigelser. Men der skal være nok data til at teste netværket på, så det er lidt af en afvejning. I vores tilfælde kan vi bruge 2/3 af blomsterne (100) til træningssættet og resten (50) til testsættet (hvis du gerne vil læse mere om træning af et netværk, kan du se denne artikel).
Når vi først giver netværket træningssættet, kender det ikke den korrekte kategori for hver blomst, og det gætter i grunden. På dette tidspunkt siger vi, at netværket er utrænet. Vægtene er tilfældige tal, mens bias er nul (figur 2A). Vi fodrer netværket med alle egenskaberne for de 100 blomster fra træningssættet og beder det forudsige, hvilken type blomst dataene stammer fra. I begyndelsen vil outputtet ofte være forkert, og vi fortæller netværket, når det tager fejl. Vi kan udtrykke, hvor forkert netværket er, hvilket kaldes den fejl. I starten af træningen vil fejlen være stor, men efter hver gennemløb justerer netværket sine vægte og bias for at mindske fejlen. Trin for trin lærer netværket mønstre i dataene og begynder at forudsige de korrekte kategorier for hver præsenteret blomst. For vores netværk tog træningsfasen ca. 5 sekunder – men for store datasæt kan det tage timer eller længere (prøv nu Øvelse 4 i Boks 4).
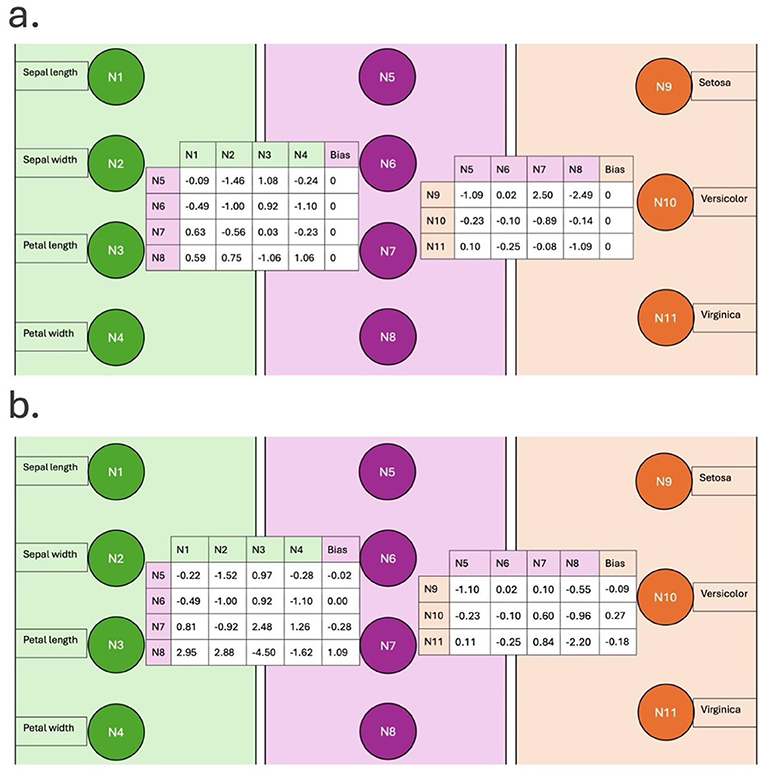
Efter tilstrækkelig træning vil fejlen blive meget lille, og netværket vil finde frem til bestemte vægte og bias (figur 2B).
Disse tal er dog ret meningsløse ved første øjekast. Derfor betragtes netværk som sorte kasser. Alligevel vil det sandsynligvis komme med de rigtige forudsigelser. Der er dog en hage: netværket har fundet frem til vægte og bias, der er optimale for træningssættet. Hvad ville der ske, hvis vi viste netværket nye eksempler på irisblomster, som det aldrig har set før? Dette er den ultimative test, og derfor kalder vi dette for at “teste netværket”. Vi gør dette ved hjælp af det testsæt med blomsterdata, som vi oprettede tidligere. For disse nye data beregner vi ofte netværkets nøjagtighed for at bestemme dets ydeevne. Nøjagtigheden er den procentdel af blomster, der forudsiges korrekt. Ofte vil nøjagtigheden ikke være 100 %. Værdier mellem 90 og 100 % betragtes som ret gode (prøv nu øvelse 5 i boks 5).
Forestil dig, at vi har trænet et netværk og ønsker at bestemme dets nøjagtighed. Vi indlæser 60 nye blomsterobservationer, og netværket forudsiger korrekt kategorien for 54 observationer. Beregn nøjagtigheden for dette netværk. (Se boks 6 for svarene på øvelserne).
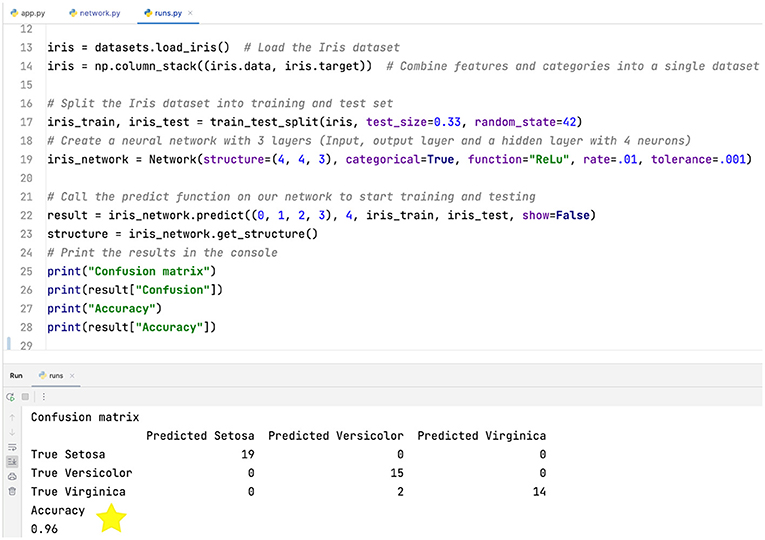
Det er endelig tid til at bruge vores netværk (fra figur 1C) til at forudsige kategorierne for vores testsæt. (Du kan selv prøve det på denne hjemmeside.) Figur 3 viser et kodestykke til at oprette og køre vores netværk (du behøver ikke at forstå kodestykket). Nederst i figuren vises resultaterne i form af en forvirringsmatrix og netværkets nøjagtighed. Lad dig ikke forvirre af forvirringsmatricen! Den viser blot de korrekte og forkerte forudsigelser. Rækkerne henviser til de rigtige blomsterkategorier, mens kolonnerne repræsenterer de kategoriforudsigelser, som netværket har foretaget. Så alle de korrekte forudsigelser ender langs diagonalen, mens forkerte forudsigelser vises i de øvrige celler. Vores netværk klassificerede fejlagtigt to virginica-blomster som versicolor, så vi endte med en nøjagtighed på 96 %. Husk, at vores netværk aldrig har set disse 50 blomster før og alligevel formåede at bestemme den rigtige kategori for 48 af dem. Ret imponerende, ikke?
Selvom neurale netværk kan virke seje, har de visse mangler. For det første siger vi ofte, at disse netværk er sorte kasser. Det betyder, at vi ikke ved, hvordan egenskaberne bruges til at forudsige blomsternes kategorier. For eksempel kan det være, at en enkelt egenskab, såsom kronbladets bredde, er meget vigtig for at forudsige blomsterkategorien. Netværket ville ikke være i stand til at fortælle os dette. Der findes andre algoritmer, der kan forklare deres beslutning under forudsigelsen. Et eksempel er multipel lineær regression, som du kan læse om i denne artikel.
Et andet problem er, at netværkets ydeevne i høj grad afhænger af træningsdataene. De endelige vægte og bias er baseret på træningsdataene. Disse vægte og bias bruges derefter til at forudsige kategorier for de nye testdata. Forestil dig, at træningsdataene ikke ligner de faktiske irisblomster og derfor er meget forskellige fra testdataene. For eksempel kan det være, at træningsdataene af en eller anden grund kun stammer fra blomster i hver kategori med meget små kronblad og bægerblad i bredde og længde. Hvis vi træner vores netværk med dette usædvanlige sæt træningsdata, vil vægtene og biasene være forankret i disse data. Så når vi fodrer det trænet netværk med tilfældige nye blomster (testsættet), vil dets ydeevne sandsynligvis være dårlig.
Neurale netværk bruger inputinformation om et objekt (f.eks. kronbladets og bægerbladets bredde på en blomst) til at forudsige noget om det pågældende objekt (f.eks. blomstens undertype). Netværket har vægte og bias, der opdateres under træningsfasen. Under testfasen kan netværket ofte forudsige nye observationer, som det aldrig har set før, med god nøjagtighed. Så for at vende tilbage til vores oprindelige eksempel har ChatGPT lært svaret på mange forskellige input-prompter og kan nu tage din besked og forudsige et nyttigt svar!
Neurale netværk: En kompleks funktion, der skaber output baseret på input.
Algoritme: En proces, der løser et specifikt problem baseret på et sæt matematiske regler.
Dataset: En struktureret samling af data med variablerne i kolonnerne og observationerne i rækkerne.
Bias: I forbindelse med neurale netværk henviser dette til et tal, der er knyttet til hver neuron, og som hjælper netværket med at bestemme den korrekte kategori.
Fejl: Et tal, der angiver, hvor forkert netværket er, når det forudsiger kategorierne.
Forvirringsmatrix: En tabel, der viser antallet af korrekte forudsigelser på diagonalen, mens de forkerte forudsigelser er i de andre celler.
[1] Menczer, F., Fortunato, S., og Davis, C. A. 2020. A First Course in Network Science. Cambridge, Storbritannien: Cambridge University Press.
[2] Newman, M. 2018. Networks, 2. udgave. Oxford, Storbritannien: Oxford University Press.
[3] Hebb, D. 1949. The Organization of Behavior. New York, NY: Wiley.
Du har sikkert hørt om ChatGPT eller måske endda allerede brugt det. ChatGPT er en interaktiv chatbot, der kan generere detaljerede svar på alle mulige spørgsmål. Den kan endda skrive dine skoleopgaver for dig. Men hvordan ved den, hvordan den skal besvare dine spørgsmål så detaljeret? ChatGPT består af neurale netværk, der gør det muligt for chatbotten at besvare dit spørgsmål. I denne artikel vil vi se nærmere på disse neurale netværk.
…
Mad gør mere end at holde os i live – den former vores sundhed og planetens sundhed. Over hele verden stiger fedmeprocenten hurtigere end nogensinde, delvis på grund af udbredelsen af ultraprocesserede fødevarer (UPF’er) – emballerede produkter som chips, forarbejdet kød, kager og sukkerholdige drikkevarer, der er billige, praktiske og svære at modstå. At spise for mange UPF’er kan føre til fedme og andre sundhedsproblemer, mens produktionen af dem skader miljøet gennem forurening, skovrydning og udledning af drivhusgasser. Klimaforandringer og tab af jord gør det sværere at dyrke den mad, vores kroppe har brug for. Disse problemer hænger sammen, men det gør løsningerne også: at spise sund, plantebaseret mad, opbygge mere retfærdige fødevaresystemer og lære, hvordan vores madvalg påvirker den verden omkring os. I denne artikel beskriver vi de overraskende sammenhænge mellem klimaforandringer og fedme, forklarer deres fælles årsager, konsekvenser og løsninger – og hvordan din generation kan være med til at gøre tingene bedre.
…
Mange teenagere i dag bruger for meget tid på at sidde ned, hvad enten det er i skolen, derhjemme eller andre steder, hvilket fører til træthed, manglende energi, tristhed eller endda helbredsproblemer. En undersøgelse i Østrig havde til formål at undersøge, om aktiv mobilitet, såsom at gå eller cykle, kunne forbedre teenagernes velbefindende. Forskerne fulgte de daglige rejser, bevægelser og trivsel hos elever i alderen 12–14 år i løbet af en uge. Resultaterne viste, at fysisk aktivitet, såsom at gå rundt uden et specifikt mål, øgede børnenes trivsel betydeligt. Når aktiv transport som at cykle eller gå til skole blev inkluderet, var teenagere mere tilbøjelige til at opfylde Verdenssundhedsorganisationens anbefalede 1 times fysisk aktivitet om dagen. Undersøgelsen viste, at selvom regelmæssig motion med moderat eller høj intensitet er meget vigtig, var det nyttigt for at forbedre trivsel at integrere aktiv mobilitet i hverdagens aktiviteter. Disse resultater understreger, hvor stor betydning enkle, daglige bevægelser har for at forbedre den generelle sundhed og lykke.
…
Tænk på sidste gang, du gjorde noget, som du senere fortrød. Måske snoozede du din vækkeur, da den ringede, faldt i søvn igen og vågnede derefter i panik over, at du ville komme for sent i skole. Du ville måske ønske, at du var stået op tidligere. Måske besluttede du at vælge pizzaen på menuen, men da din søskendes pasta så lækker ud, ønskede du, at du havde valgt noget andet. Dette er eksempler på fortrydelse. Fortrydelse er noget, som alle mennesker føler fra tid til tid, og det spiller en vigtig rolle i at hjælpe os med at beslutte, hvordan vi skal opføre os. I denne artikel vil vi undersøge, hvad fortrydelse er, hvordan vi ender med at føle det, og hvorfor det er så vigtigt.
…